Pelikan Software
Pelikan Software is a private software company founded by a group of software developers. We are developing products for printing and digital publishing. All products are available for download and purchase. Learn more.
Pelikan Software helps professionals, publishers, businesses, home users create, print and publish documents.
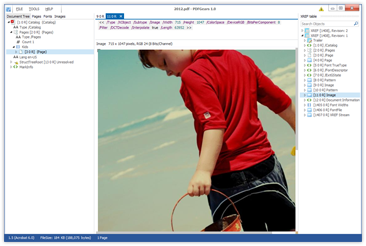
PDF Gears
PDF Gears is a powerful PDF Inspector. It can open PDF file and display it's internal structure in the most convenient way. Even syntax of page content stream is highlighted. Even description for all commands is displayed.
Images can be displayed as ... images. HEX viewer sometimes is a good choice as well.
Must have tool for all PDF developers.
priScanner Express
priScanner Express is a powerful, easy to use scanning programm. It offers different but intuitive way for scanning images and documents. Large preview area, inplace scanning, single click copy to printer functionality.
priPrinter
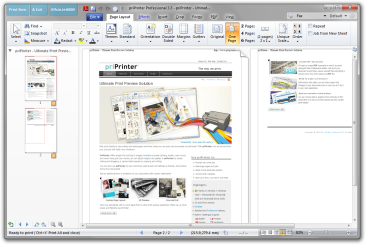
priPrinter is a virtual printer with powerful and interactive print preview. With priPrinter you may print from any application with printer support, preview and check pages in many ways and print to a real printer after that. priPrinter may print to any printer in single or double sided mode.
priPrinter supports multiple pages on a single paper sheet. Page layout is very flexible and can be selected from a predefined list or changed on the fly. Booklets and posters are fully supported. priPrinter is able to remove empty pages and big margins, footers or headers. priPrinter supports watermarks, page numbers and more. Also you may measure graphics on the page, check used fonts and bitmaps, search for specific phrase. In addition, you can print to images.
priPrinter Professional is an extended version of priPrinter. In addition to all priPrinter features it provides the following features:
- Creation of PDF documents right from print preview window.
- Buit in text editor with ability to edit text, change font, size and color. Text could be highlighted or redacted.
priPrinter Professional allows you to create PDF files with just one mouse click. PDF could be saved to disk or emailed using your email client. priPrinter Professional automatically selects best compression algorithm for images, embeds all required fonts. Not used glyphs are removed. PDF files could be encrypted.